Activation function 종류별 성능
1. Adam
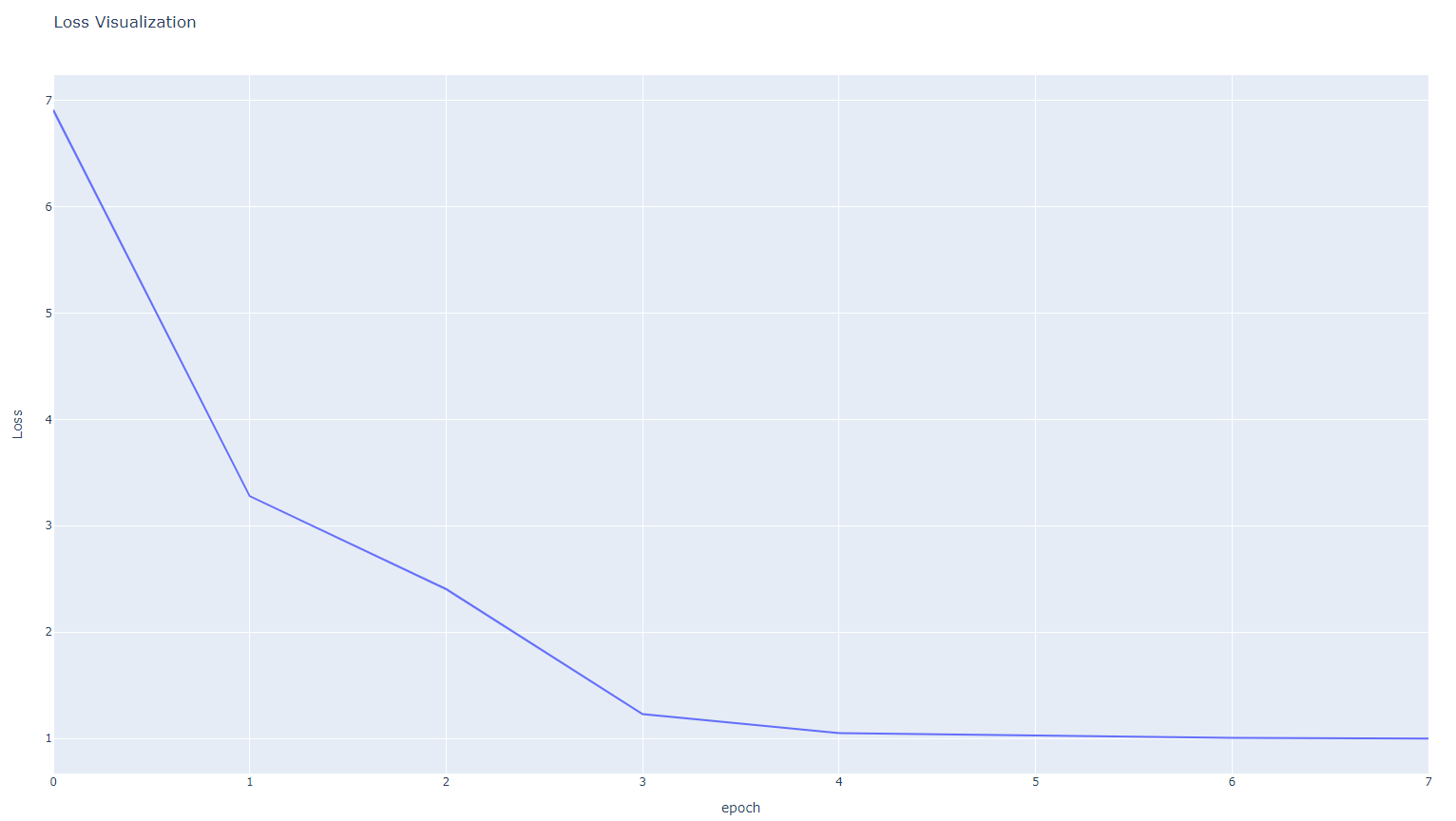
2. Adamax

3. ASGD

4. Rprop
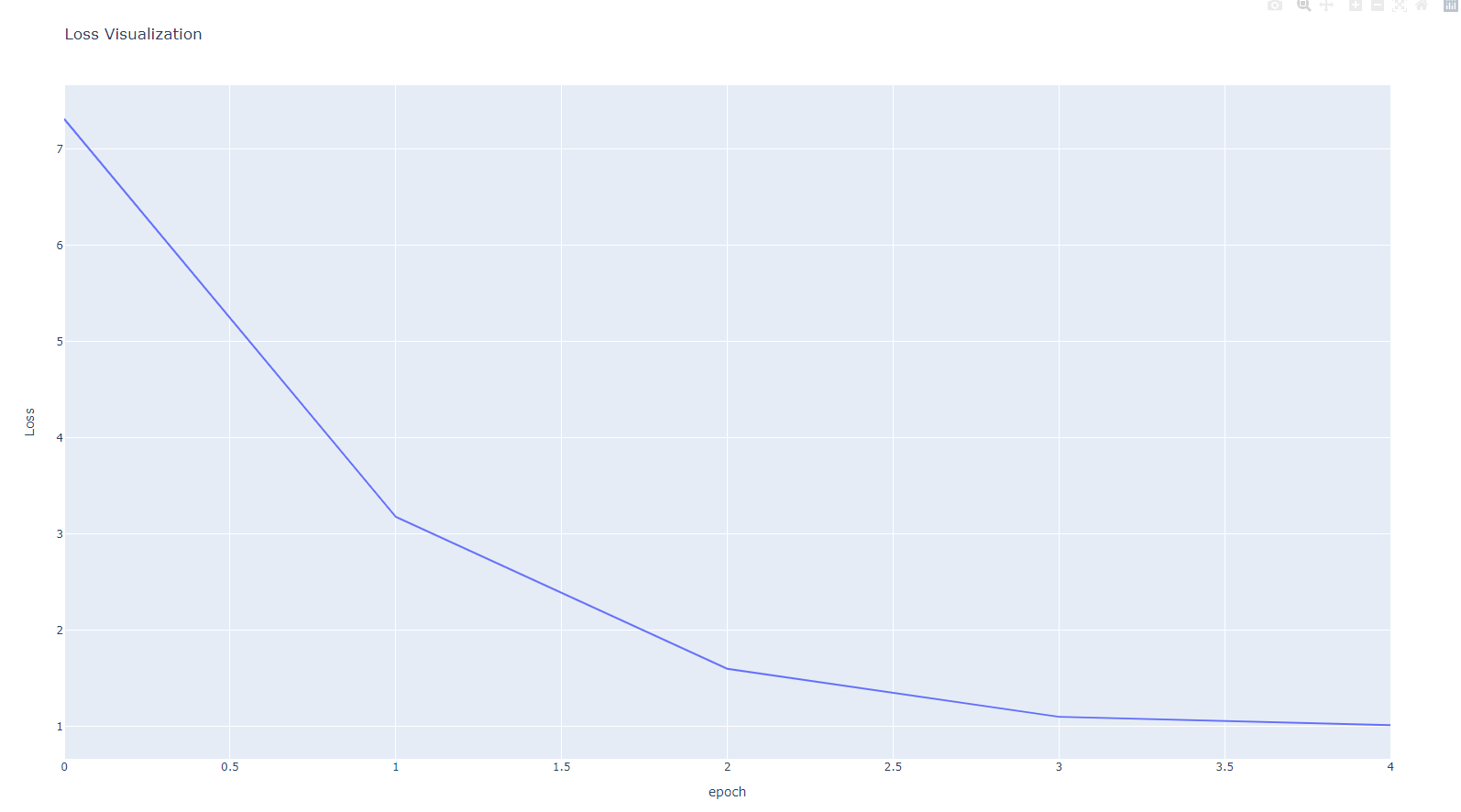
Learning Rate별 성능
MESLoss, Adam Activation Function으로 진행. loss가 1보다 작아질 때까지 돌림.
1. lr = 0.0001

2. lr = 0.00001
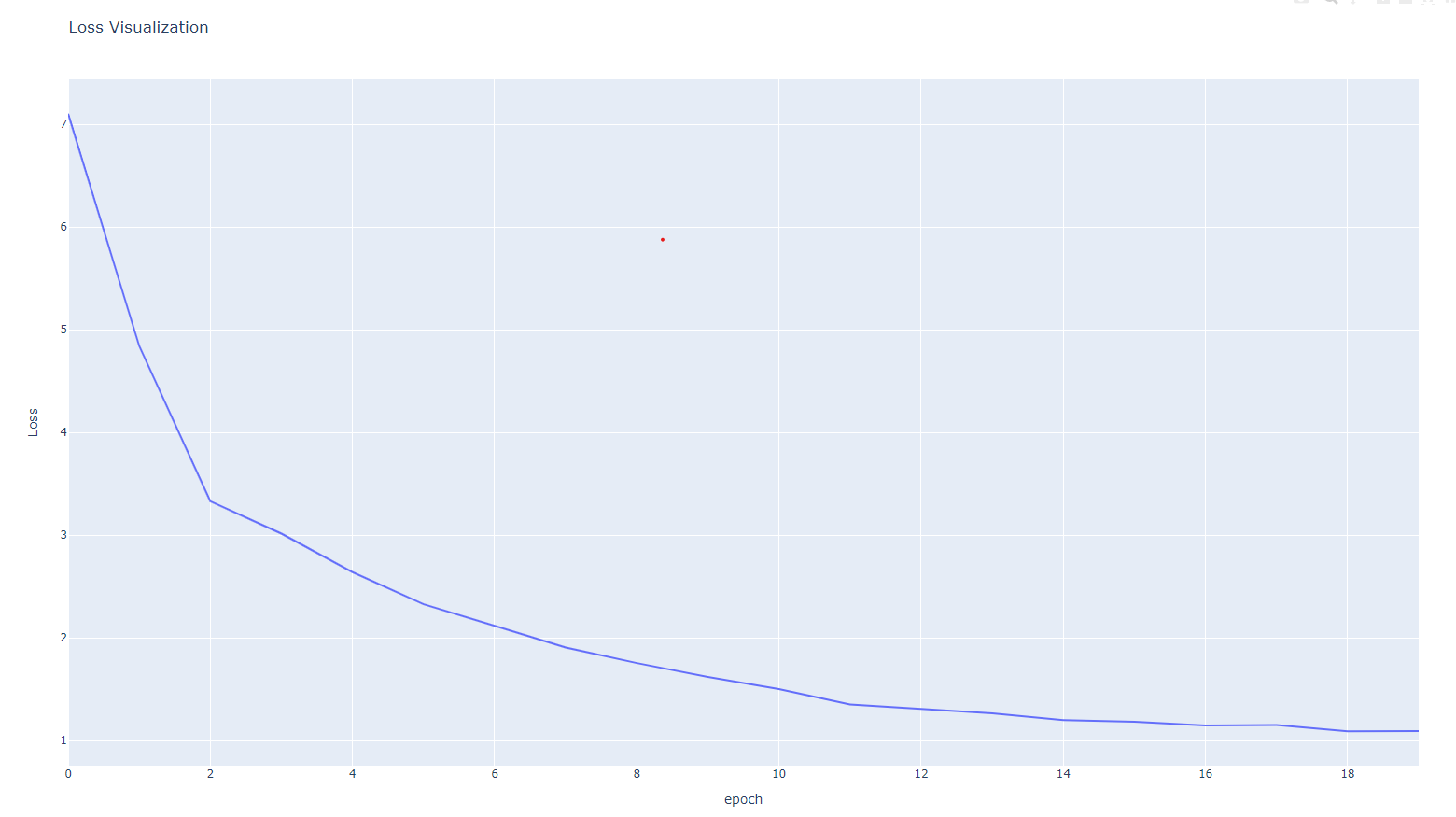
3. lr = 0.00005
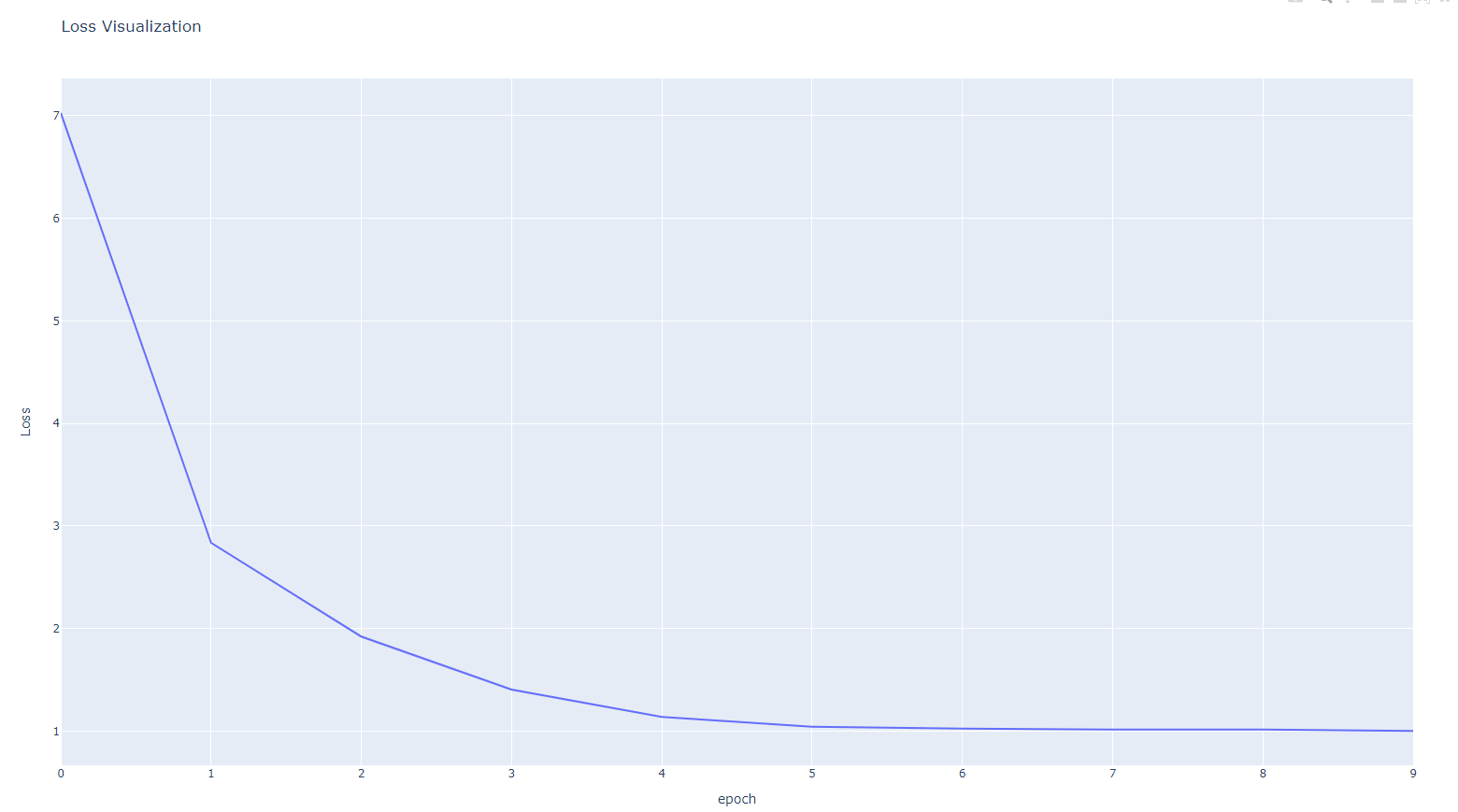
4. lr = 0.000005

5. lr = 0.000001

Loss Function 별 성능
lr = 0.00001, optimizer = Adam
1. MSELoss()
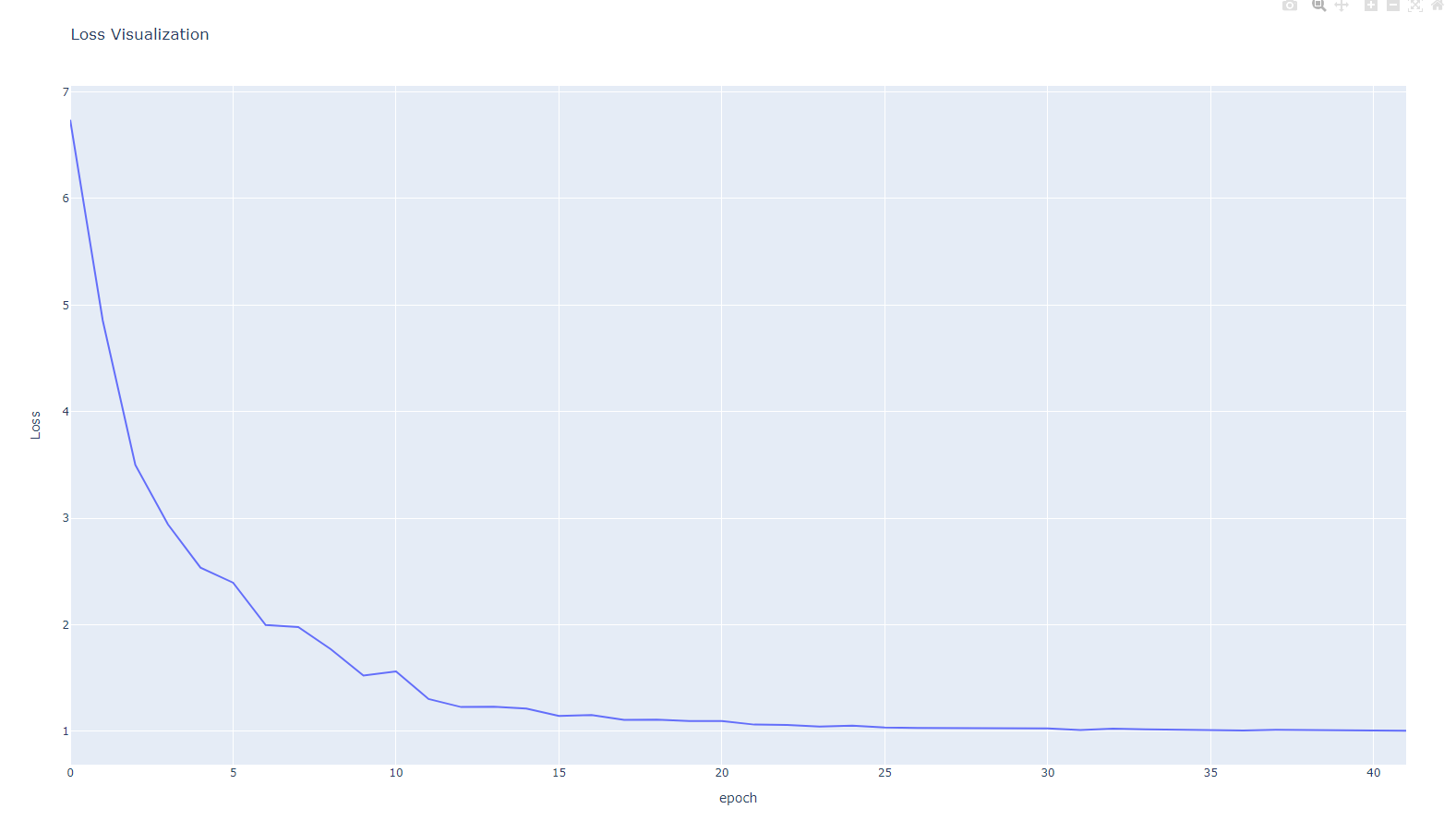
2. SmoothL1Loss()
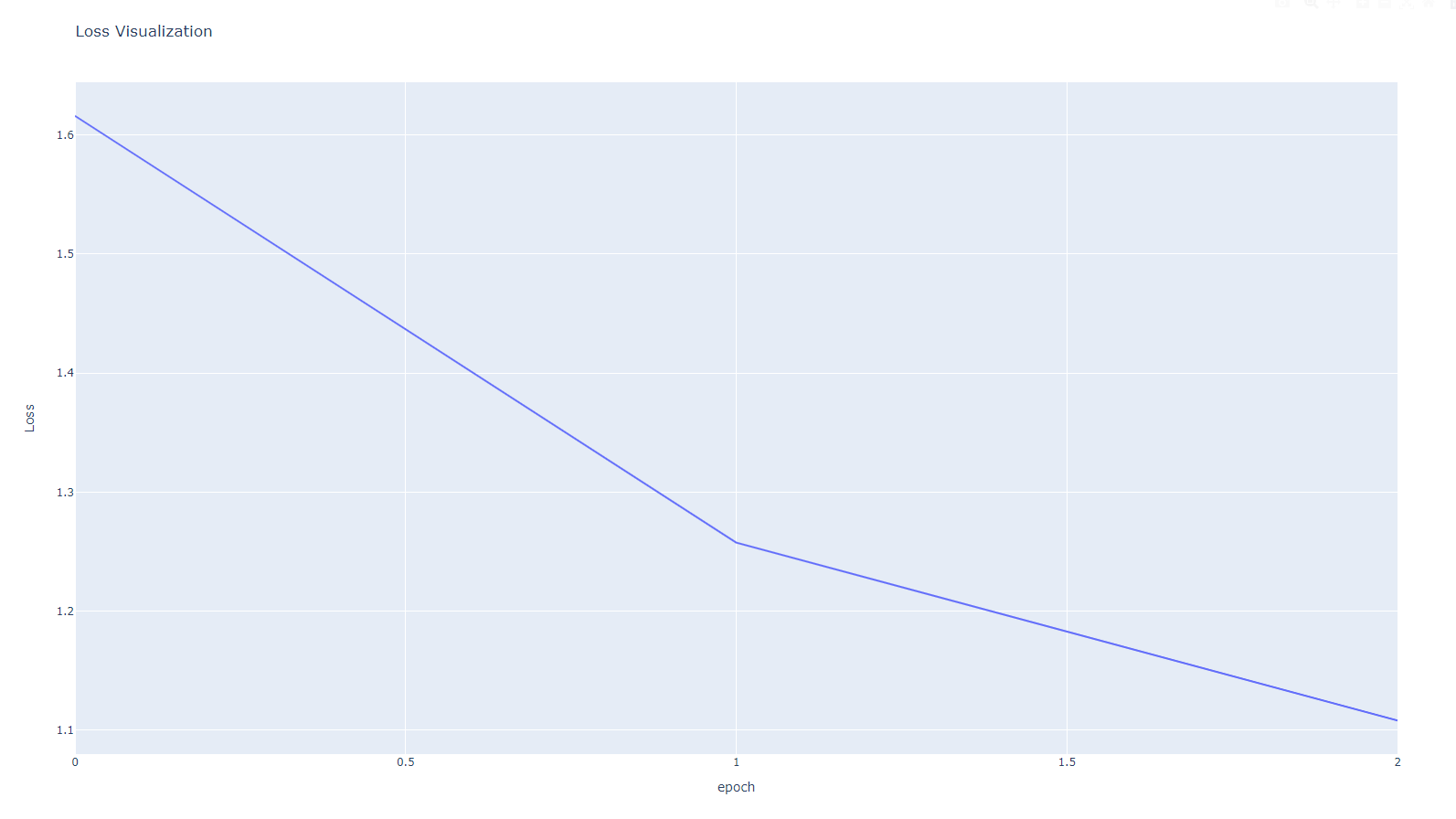
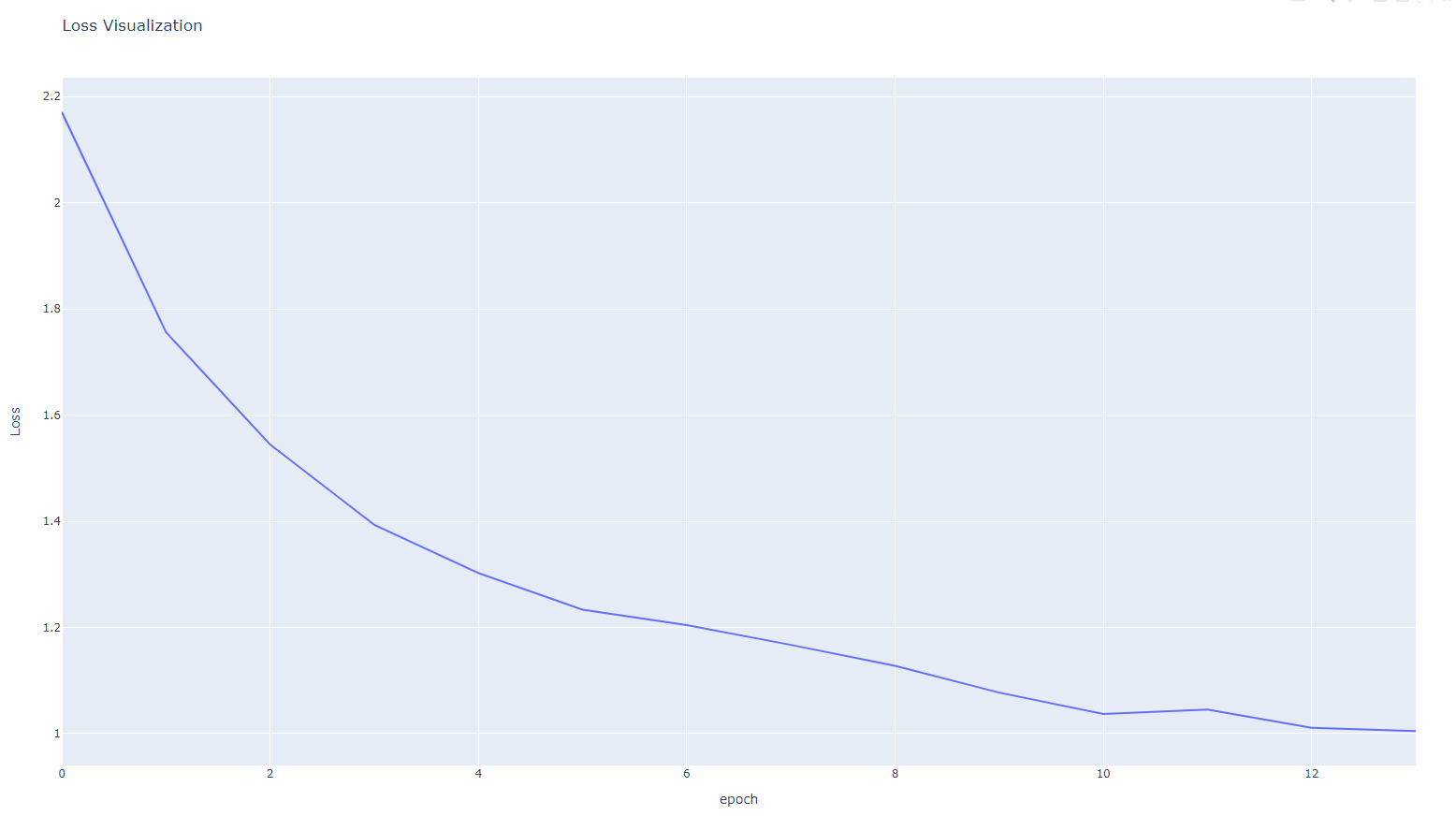
3. L1Loss()
베이스코드
#Pretrained NN이 항상 1이 나오도록 학습시킨다.
#Gound Truth를 1로 넣어주고 학습 시킨 후 모델 저장, 이후 test 해보면 1에 가까운 값이 나온다.
#하지만 1을 넘기는 값이 나오는 문제가 발생.
#파이썬 기반의 계산 라이브러리. 딥러닝 모델을 쉽게 구성하고 학습시킬 수 있다.
import torch
#PyTorch 라이브러리에서 제공하는 신경망 모듈을 사용하기 위한 코드. nn.Module 클래스를 상속받아 신경망 모델을 정의할 수 있다.
import torch.nn as nn
#PyTorch 라이브러리에서 제공하는 이미지 분류를 위한 대표적인 딥러닝 모델인 VGG, ResNet, DenseNet 등을 제공한다.
import torchvision.models as models
from torch.autograd import Variable
from torchsummary import summary
#데이터 시각화를 위한 Plotly 라이브러리를 불러온다.
import plotly.express as px
#데이터 분석을 위한 라이브러리
import pandas as pd
#PyTorch에서 제공하는 변수 클래스 Variable을 불러온다. Variable은 tensor를 래핑한 객체이다.
from torch.autograd import Variable
#PyTorch 모델의 구조를 출력하는 함수 summary를 사용하기 위한 코드. 모델의 구조와 파라미터 수 등을 쉽게 확인할 수 있다.
from torchsummary import summary
#import os
#os.environ["LMP_DUPLICATE_LIB_OK"] = "TRUE"
#cuda로 보낸다
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('========VGG 테스트 =========')
print("========입력데이터 생성 [batch, color, image x, image y]=========")
#이미지 사이즈를 어떻게 잡아도 vgg는 다 소화한다.
#==========================================
#1) 모델 생성
model = models.vgg16(pretrained=True).to(device)
print(model)
print('========= Summary로 보기 =========')
#Summary 때문에 cuda, cpu 맞추어야 함
#뒤에 값이 들어갔을 때 내부 변환 상황을 보여줌
#adaptive average pool이 중간에서 최종값을 바꿔주고 있음
summary(model, (3, 100, 100))
print("========model weight 값 측정=========")
'''
for name, param in model.named_parameters():
if param.requires_grad:
print (name, param.data)
'''
#2) loss function
#꼭 아래와 같이 2단계, 클래스 선언 후, 사용
criterion = nn.MSELoss()
#criterion = nn.SmoothL1Loss()
#criterion = nn.L1Loss()
#criterion = nn.Tanh()
#criterion = nn.KLDivLoss()
#criterion = nn.NLLLoss()
#criterion = nn.CrossEntropyLoss()
#criterion = nn.MarginRankingLoss()
#criterion = nn.CosineEmbeddingLoss()
#3) activation function :
learning_rate = 0.000005
#learning_rate = 0.001 #이렇게 하면 부동 소수점 에러
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#optimizer = torch.optim.Adamax(model.parameters(), lr=learning_rate)
#optimizer = torch.optim.ASGD(model.parameters(), lr=learning_rate)
#optimizer = torch.optim.Rprop(model.parameters(), lr=learning_rate)
#모델이 학습 모드라고 알려줌
model.train()
#loss들을 담을 list
loss_list = []
#제일 큰 loss값 정의.
max_loss = 10
#epoch란 딥러닝모델에서 전체 데이터셋을 한 번 훑는 과정.
epoch = 0
#epoch를 담을 리스트.
epoch_list = []
#----------------------------
#epoch training
#for i in range (10):
while True:
#옵티마이저 초기화
optimizer.zero_grad()
#입력값 생성하고
a = torch.randn(12,3,100,100).to(device)
#모델에 넣은다음
result = model(a)
#결과와 동일한 shape을 가진 Ground-Truth 를 읽어서
#target = torch.randn_like(result)
#타겟값을 1로 바꾸어서 네트워크가 무조건 1만 출력하도록 만든다. 오버피팅 될수도있음.
target = torch.ones_like(result)
#네트워크값과의 차이를 비교
loss = criterion(result, target).to(device)
if(loss<1.002):
break
# 배열에 차이 저장.
loss_list.append(loss.item())
epoch_list.append(epoch)
#=============================
#loss는 텐서이므로 item()
print("epoch: {} loss:{} ".format(epoch, loss.item()))
#loss diff값을 뒤로 보내서 grad에 저장하고
loss.backward()
#저장된 grad값을 기준으로 activation func을 적용한다.
optimizer.step()
epoch += 1
#epoch수와 해당epoch에서의 loss값을 갖는 데이터프레임을 만든다.
df = pd.DataFrame(dict(
epoch=epoch_list,
Loss=loss_list
))
#위에서 정의한 데이터프레임을 이용하여 loss값의 변화를 시각화하는 그래프 생성.
fig = px.line(df, x="epoch", y="Loss", title='Loss Visualization')
#그래프 출력
fig.show()
print("=========== 학습된 파라미터만 저장 ==============")
torch.save(model.state_dict(), 'trained_model.pt')
print("=========== 전체모델 저장 : VGG 처럼 모델 전체 저장==============")
torch.save(model, 'trained_model_all.pt')'수업내용 정리' 카테고리의 다른 글
| [인공지능 응용] loss값을 동적으로 조절하기 (0) | 2023.05.12 |
|---|---|
| [인공지능 응용] Tensorboard로 그래프 출력하기 (0) | 2023.05.12 |
| [인공지능 응용] CIFAR10 예제 공부하기 (0) | 2023.04.06 |